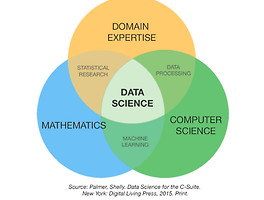
개린이의 IT 일상 (8) 썸네일형 리스트형 인공지능과 데이터 I. 데이터 사이언스란? 통계적 분석기법, 과학적 방법론, 분석 프로세스, 알고리즘, 시스템 등을 활용하여 다양한 데이터로부터 새로운 지식과 인사이트를 추출하는 융합분야 II. 데이터 분석 프로세스 1. 기획 : 해결할 문제 정의, 분석 방법론 및 설계도 작성 2. 수집 : 데이터 수집, 오류(이상치, 결측치 등) 정리 3. 분석 전처리 (데이터 탐색 및 정제) 기술 통계 분석 (집단 간 비교, 시계열 비교) 가설 검정 예측 모형 개발 및 고도화 4. 보고 (시각화-BI, 대시보드) III. 머신러닝(기계 학습)이란? 1. 정의 말 그대로 컴퓨터를 학습시키는 방법이다. 데이터를 활용하여 인간의 사고 과정을 경험할 수 있도록 컴퓨터를 훈련시킨다. 2. 과정 기존의 데이터로 모델을 학습시켜 도출된 내용으로 .. 파이썬 개발 환경 구축 및 관계형 데이터베이스(ft.Git_SQL) I. 개발 환경 1. 터미널 글자 기반 명령을 전달할 수 있는 어플리케이션 2. CLI; Command Line Interface 글자 기반 명령과 결과가 진행되는 환경 개발 도구들이 주로 CLI를 기반으로 만들어졌기에 필수적으로 공부해야함 맥/리눅스-기본터미널 및 iterm, 윈도우-git bash를 활용하여 CLI 이용함 GUI: 그래픽 기반 환경 3. 가상환경 어플리케이션 개발하는 환경 독립시키고 배포 환경에서도 개발 환경이 똑같이 재현될 수 있도록 함 하나의 파이썬 환경에는 하나의 파이썬의 패키지당 하나의 버전만 설치될 수 있음 두 개의 어플리케이션을 개발하는 상황에서 서로 다른 패키지 버전이 필요하다면, 즉 동시에 하나의 환경에서 두 가지의 패키지 버전이 필요한 상황에서는 패키지간 충돌이 일어남.. [ML] Preprocessing_ModelTuning(ft.아무_생각_없음) 느낀 점 히이이이이ㅣㅣ 아무 생각 없다 Section2_Sprint2_Note3&Note4 Preprocessing 특성과 전처리의 관계 결측치 처리 수치형 변수 전처리 범주형 변수 전처리 Model Tuning 하이퍼파라미터 튜닝 특성 선택 요약 : 전처리 과정이 제일 복잡하고도 복잡하다. 특성과 전처리의 관계 각기 다른 모델 유형에 따른 각기 다른 전처리 특성 선형 회귀 기반 모델 (LInear / Logistic Regression)등 → 대수적 연산으로 예측이 이루어지는 경우 ** 대수적 연산 : y = a*x + b 입력 특성들의 크기 / 범위 / 분포에 영향을 받는다. 입력 값 자체가 직접 대수적 연산에 사용되므로, 입력 값들의 대소관계 뿐만 아니라 값의 분포나 크기, 범위 자체도 모델의 성능.. [ML] Bagging_Boosting(ft.멘탈_파사삭) 느낀 점 을 표현하기에 글보단 사진이 나을 것 같다. Section2_Sprint2_Note1&Note2 트리 기반 모델(tree-based model) 비선형, 비단조, 특성상호작용 특징을 가진 데이터 분석 용이 앙상블 모델을 결정트리를 기본 모델로 한다. 결정트리 : 비용함수를 최소화하는 방향으로 데이터 분할 회귀와 분류 모두 적용 가능 분류 문제의 비용함수 - 불순도 회귀 문제의 비용함수 - MSE 분류 문제의 예측값 - 마지막 노드에 있는 타겟값들의 최빈값 회귀 문제의 예측값 - 마지막 노드에 있는 타겟값들의 예측값 직관적이며 시각화가 가능한 데이터 분할 과정 - 해석하기 용이함 제약 사항이 거의 없는 유연한 모델 - 과대적합 위험 from sklearn.tree import DecisionTre.. [ML] LinearRegression_선형회귀 (ft. 절겁다) Section2가 시작되었다아아 Section1 마무리 기간에 개인적으로 많이 힘들었다ㅠㅠㅠ 그래도 스스로 토닥토닥해주며 보내주기로 했다! 그래야 Section2를 시작할 수 있을 것 같았다 이제 그만 우울을 떨치고!! 머신러닝 학습이 시작되었다아아 어려울 것이라고 생각하고 쫄고 있었는데ㅋㅋ 오오 생각보다 재미있었다 !!! 진짜루 절거웠다 휴 Section2_Sprint1_Note1 학습목표 머신러닝과 지도학습 이해 회귀 문제(모델) 이해 회귀 모델에 대한 기준 모델 설정 회귀 평가지표 이해 및 적절한 사용 선형 회귀 모델 이해 단순선형/다중선형/다항선형 회귀의 차이 이해 Scikit-learn 이용한 선형 회귀 모델 생성, 사용, 해석 기존의 데이터로 유의미한 학습을 하고, 그 학습 결과를 토대로 새로.. Statistic_통계 (ft.내_머리) 1주차 개강 첫날이 가장 멘붕이었고 이후로는 이만큼의 충격은 없을 것이라고 확신하고 있었던 과거의 나,, 미래 예측 따위는 절대 다시 하지말자 역시 뜻대로 되지 않는 인생사 새옹지마아아아ㅏㅏㅏ 겨우 데이터 분석의 첫 단계를 입문하였을 뿐인데 나는 왜 벌써부터 머리를 쥐어뜯고 있는 것인가 요즘 나의 최대 고민은 부캠 끝마칠 때 나의 머리는 온전할까이다..ㅎ 이번 주말도 월요일의 스챌(한주를 마무리하는 시험) 준비로 빠듯하당 아이 신나 아이 행복해 Section1_Sprint2 학습목표 베이지안 정리 (Bayesian Theorem) 중심극한정리 (Central Limit Theorem) 가설 검정 (Hypothesis Test) AB테스트 (AB Test) 모든 데이터 분석은 통계에서 출발하며, 통계의 본.. EDA 와 Data Wrangling (ft. 첫_시험) 오늘 첫 스챌(스프린트챌린지; 한주동안 배운 내용 시험)을 진행했다. 사실 엄청나게 멘붕이 올 줄 알았는데 나름 괜찮았다. 아무래도 주말동안 최선을 다해 공부했던 것이 조금 도움이 됐나보다. 다행스럽게도? 흥미가 느껴진다. 첫 날에는 진짜 대혼란을 맞이했었는데 고작 일주일?도 아니다,, 5일차라고 개미눈물만큼의 적응이 되었다. 이것으로 만족하는 Sprint1을 보내주게 되었다. 몇개월차의 짬이 찼을 때에 해당 글을 다시 본다면 제발 보다 쉽게 느껴지기를 Section1_Sprint1_WrapUp 본격적인 데이터 분석 및 모델링 전에, 데이터를 탐색하고 정제하는 과정이 필요하다. EDA EDA: 데이터 타입/규모/오류/분포/컬럼별 상관관계 확인 Feature Engineering: 기존 feature 재조.. EDA (ft. AI_bootcamp_개강) 글을 쓰는 현재 시점은 개강 첫주 주말이다. 돌아오는 월요일에 한주 동안 배운 내용을 시험본단다. 정말 이렇게까지 머리가 터질 것 같다는 느낌 오랜만이다. 아무래도 컴퓨터 관련 전공자가 아니기에 그런가보다. 평일에 약간의 고비가 있었지만, 인간이라면 누구나 처음 접해보는 것에 미숙하다 라는 생각으로 조급해하지 않고 자신에게 실망하지 않고, 내가 할 수 있는 만큼의 최선을 다해 하루를 보내보자 라는 긍정 마인드를 다시 되새긴다. 아직 할일이 산더미인데 벌써 일요일 저녁 아홉시이다. 안녕 나의 주말,, Section1_Sprint1_Note1&Note2 학습목표 EDA에 대해서 이해한다. Feature Engineering의 목적을 이해할 수 있다. Business Insight를 도출할 수 있다. 통계 및.. 이전 1 다음